(メモ) LlamaIndexだけを利用して多段推論を試してみる
以下の記事で、LlamaIndexのqueryだけでは文書を参照した多段推論(問いが複数のステップに分解され、それぞれのステップにおいて文書を参照して解く必要があるタスク)が解けないため、LangChainのAgentと組み合わせて使用することを試みました。
しかしLlamaIndexのドキュメントを読んでいると、多段推論が可能な機能が公開されていることに気付きました。

StepDecomposeQueryTransformとMultiStepQueryEngineを利用することで、上図のように問いを分解し、それぞれの問いを解くために外部データを参照するプロセスが実現可能となるようです。
そこでhttps://tripdancer0916.hatenablog.com/entry/llamaindex_agent の記事同様に関内のWikipediaを外部データとして、以下の問いに答えられるかを試します。
横浜三塔の歴史を日本語で答えてください。
ちなみに横浜三塔とはキングの塔(神奈川県庁本庁舎)・クイーンの塔(横浜税関)・ジャックの塔(横浜市開港記念会館)のことです。
MultiStepQueryEngineの活用
example notebookを参考に、以下のようなコードを書きました(関連する箇所のみ抜粋)。
from llama_index.indices.query.query_transform.base import StepDecomposeQueryTransform from llama_index.query_engine.multistep_query_engine import MultiStepQueryEngine step_decompose_transform = StepDecomposeQueryTransform( llm_predictor, verbose=True ) index_summary = "横浜三塔と呼ばれる塔の名前を調べるのに利用します。" query_engine = index.as_query_engine( text_qa_template=QA_PROMPT, refine_template=REFINE_TEMPLATE, service_context=service_context, similarity_top_k=5, ) query_engine = MultiStepQueryEngine( query_engine, query_transform=step_decompose_transform, index_summary=index_summary, ) response = query_engine.query( '横浜三塔の歴史を日本語で答えてください。', ) print(response)
ここで、index_summaryには外部データの説明(どのように活用するか)を記述します。AgentにおけるToolのdescriptionのようなイメージですね。
tools = [
Tool(
name = "WikipediaSearch",
func=lambda q: str(query_engine.query(q)),
description="Wikipediaのページから検索します。"
),
]
ただし、Agentの時よりも具体で活用法を書かないと上手く動かないようでした。
実行結果
実際に上記コードを実行してみると、以下のようなプロセスが得られました。
> Current query: 横浜三塔の歴史を日本語で答えてください。 > Formatted prompt: The original question is as follows: 横浜三塔の歴史を日本語で答えてください。 We have an opportunity to answer some, or all of the question from a knowledge source. Context information for the knowledge source is provided below, as well as previous reasoning steps. (中略) Question: 横浜三塔の歴史を日本語で答えてください。 Knowledge source context: 横浜三塔と呼ばれる塔の名前を調べるのに利用します。 Previous reasoning: None New question: > New query: What are the names of the towers referred to as Yokohama San-tower?
(中略)の中身ですが、以下のようなQuestionとKnowledge source context, New questionのペアが例示として複数与えられます。
Question: How many Grand Slam titles does the winner of the 2020 Australian Open have? Knowledge source context: Provides names of the winners of the 2020 Australian Open Previous reasoning: None Next question: Who was the winner of the 2020 Australian Open?
プロンプトによって、Chain-of-Thoughtが行われるようです。
このプロセスにより、
New query: What are the names of the towers referred to as Yokohama San-tower?
という、「まず横浜三塔の名前を調べる」という推論フェーズに入ることが確認できました(index_summaryで天下り的に与えてしまっているのでアレですが・・)。
いくつかの推論プロセスを経て、以下のような回答が得られました。
Question: 横浜三塔の歴史を日本語で答えてください。 Knowledge source context: 横浜三塔と呼ばれる塔の名前を調べるのに利用します。 Previous reasoning: - What are the names of the towers referred to as Yokohama San-tower? - The names of the towers referred to as Yokohama San-tower are King's Tower (Kanagawa Prefectural Government Building), Queen's Tower (Yokohama Customs), and Jack's Tower (Yokohama Port Opening Memorial Hall). - What are the names of the towers referred to as Yokohama San-tower? - The names of the towers referred to as Yokohama San-tower are King's Tower (Kanagawa Prefectural Government Building), Queen's Tower (Yokohama Customs), and Jack's Tower (Yokohama Port Opening Memorial Hall). New question: > New query: None. INFO:llama_index.token_counter.token_counter:> [get_response] Total LLM token usage: 450 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total embedding token usage: 0 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total LLM token usage: 450 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total embedding token usage: 0 tokens 横浜三塔は、横浜港開港記念館(ジャックスタワー)、神奈川県庁舎(キングスタワー)、横浜税関(クイーンズタワー)の3つの建物からなる横浜のランドマークです。横浜港開港記念館は、1859年に横浜港が開港したことを記念して建てられました。神奈川県庁舎は、1926年に完成しました。横浜税関は、1930年に完成しました。
New queryがNoneになると、最終的な出力が得られるようになっています。
出てきた答えはそれっぽいですが、元のWikipediaを見るとそれぞれの完成年は
- 横浜港開港記念館: 1917年
- 神奈川県庁舎: 1928年
- 横浜税関: 1934年
なので、だいぶ間違っています。。。
プロンプトのチューニングで改善できる余地はありそうですが、パッと使った感じだとAgentの方が性能は良さそうですね。
各手法の比較
最後に、横浜三塔の歴史を日本語で答えてください。という問いに対する
- シンプルなクエリを使った場合
MultiStepQueryEngineを使った場合- Agentと組み合わせた場合
に得られた答えを紹介したいと思います。
- シンプルなクエリを使った場合
横浜三塔は、キングの塔(神奈川県庁本庁舎)、クイーンの塔(横浜税関)、ジャックの塔(横浜市開港記念会館)の3つの塔で、横浜港のシンボルとして親しまれています。地元では「横浜三塔」と呼ばれ、長年市民に愛されています。
MultiStepQueryEngineを使った場合
横浜三塔は、横浜港開港記念館(ジャックスタワー)、神奈川県庁舎(キングスタワー)、横浜税関(クイーンズタワー)の3つの建物からなる横浜のランドマークです。横浜港開港記念館は、1859年に横浜港が開港したことを記念して建てられました。神奈川県庁舎は、1926年に完成しました。横浜税関は、1930年に完成しました。
- Agentと組み合わせた場合
横浜三塔は、キングの塔(神奈川県庁本庁舎)、クイーンの塔(横浜税関)、ジャックの塔(横浜市開港記念会館)の3つの塔で、横浜港のシンボルとして親しまれています。ジャックの塔は、横浜町会所として建てられ、後に横浜市開港記念会館として再建されました。キングの塔の詳細な歴史については不明ですが、クイーンの塔は1934年に完成し、現在は横浜税関として知られています。
LlamaIndexとLangChainのAgentを組み合わせて文書を参照した多段推論を実現する
LlamaIndex概要
ChatGPTの知識を補完する仕組みとして、llama_indexがあります。 これを使うことで、文書やwebページをChatGPTに外部情報として渡してそれを参照して質問に回答してもらうことができるようになります。
使い方などは例えばこのnoteのシリーズが詳しいです。
実際に、例えば関内のwilipediaページを外部情報として与えた上で「横浜三塔と呼ばれる塔の名前を教えてください。」という質問をしてみる(LLMはgpt-3.5-turboを利用)と、
キングの塔(神奈川県庁本庁舎)・クイーンの塔(横浜税関)・ジャックの塔(横浜市開港記念会館)
という正しい答えが返ってきました。 Wikipediaには
キングの塔(神奈川県庁本庁舎)・クイーンの塔(横浜税関)・ジャックの塔(横浜市開港記念会館)は、地元では「横浜三塔」と呼ばれ、横浜港のシンボルとして長年市民に親しまれている。
という記述があるため、ここを参照にしていると思われます。
なお外部情報は以下のように与えており、正確な出力が得られるようにプロンプトテンプレートを更新しています。
BeautifulSoupWebReader = download_loader('BeautifulSoupWebReader') loader = BeautifulSoupWebReader() documents = loader.load_data(urls=['https://ja.wikipedia.org/wiki/関内']) index = GPTVectorStoreIndex.from_documents( documents, service_context=service_context, ) query_engine = index.as_query_engine( text_qa_template=QA_PROMPT, refine_template=REFINE_TEMPLATE, similarity_top_k=5, ) response = query_engine.query( '横浜三塔と呼ばれる塔の名前を教えてください。', )
テンプレートは以下です。
QA_PROMPT_TMPL = """ Let's work this out in a step by step way to be sure we have the right answer. 以下に、コンテキスト情報を提供します。 --------------------- {context_str} --------------------- このコンテキスト情報を考慮し、次の質問に回答してください: {query_str} """ REFINE_PROMPT_TMPL = """ Let's work this out in a step by step way to be sure we have the right answer. 質問: {query_str} 既存の回答: {existing_answer} 以下に、新しいコンテキスト情報を提供します。 ------------ {context_msg} ------------ 新しいコンテキスト情報を考慮し、必要に応じて既存の回答を改善してください。 """
ちなみに、通常のChatGPT(gpt-3.5 turbo)に同じ質問をしてみると以下のように間違った回答が返ってきました。
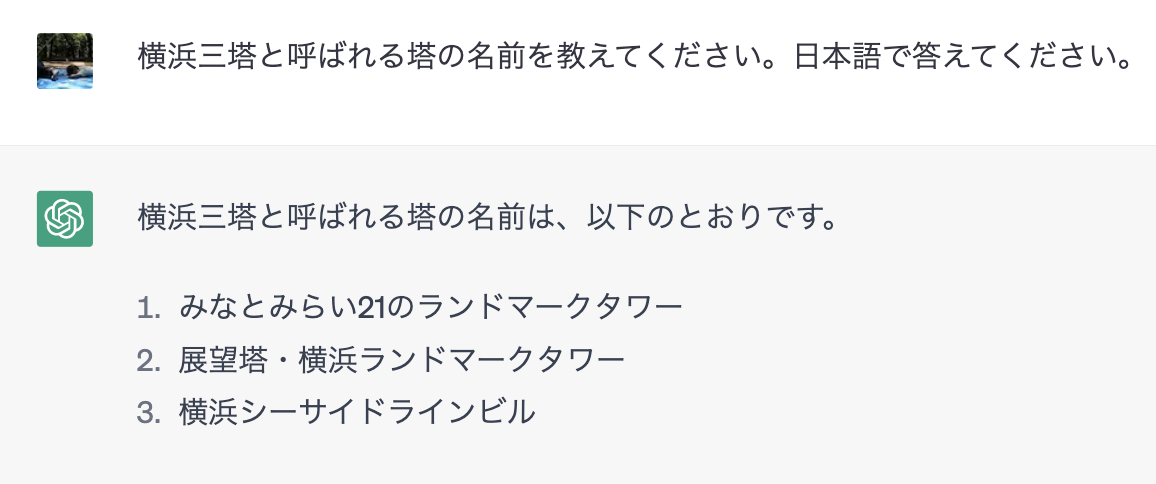
多段推論
では次に、「横浜三塔と呼ばれる塔の歴史を日本語で答えてください。」という質問をしてみようと思います。 これに答えるには、
というプロセスを踏む必要があります。
前セクションと同様に、LlamaIndexを利用して質問をしてみると以下のような答えが返ってきました。
キングの塔(神奈川県庁本庁舎)・クイーンの塔(横浜税関)・ジャックの塔(横浜市開港記念会館)は、地元では「横浜三塔」と呼ばれ、横浜港のシンボルとして長年市民に親しまれている。
どうやらプロセスの1.で止まってしまったようです。単純なLlamaIndexのquery機能では、多段推論は難しそうというのが分かります。
Agentの利用
LangChainにはAgentと呼ばれる機能があり、これを利用することでLLMが適宜Google検索や計算機にアクセスした上で必要な情報を取得してタスクを解くことができるようになります。
以下のように、このAgent機能とLlamaIndexの文書参照質問回答機能を組み合わせることで多段推論が必要な質問に回答してもらうことを試してみました。 (c.f. LLamaIndexのチュートリアルをやってみる)
tools = [
Tool(
name = "WikipediaSearch",
func=lambda q: str(query_engine.query(q)),
description="Wikipediaのページから検索します。"
),
]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run('横浜三塔と呼ばれる塔の歴史を日本語で答えてください。')
これにより、上に記したプロセスを踏んで適切に回答してくれるのではと期待できます。 実行してみると、以下のような出力が得られました。
Final Answer: 横浜三塔は、キングの塔(神奈川県庁本庁舎)、クイーンの塔(横浜税関)、ジャックの塔(横浜市開港記念会館)の3つの塔で、キングの塔とクイーンの塔は1934年に完成し、それぞれ神奈川県庁本庁舎と横浜税関として建てられました。ジャックの塔は、元々は横浜町会所として建てられ、後に横浜市開港記念会館として再建されました。
キングの塔が完成したのは1928年なのでそこだけ間違えてしまっているのですが、他は正しい答えが出力されています。
回答に至るプロセスを確認してみると以下のようになっていました。
WARNING:llama_index.llm_predictor.base:Unknown max input size for gpt-3.5-turbo, using defaults. INFO:llama_index.indices.loading:Loading all indices. > Entering new AgentExecutor chain... I'm not sure what the "横浜三塔" are, so I should search for them on Wikipedia. Action: WikipediaSearch Action Input: "横浜三塔"INFO:llama_index.token_counter.token_counter:> [retrieve] Total LLM token usage: 0 tokens INFO:llama_index.token_counter.token_counter:> [retrieve] Total embedding token usage: 9 tokens Token indices sequence length is longer than the specified maximum sequence length for this model (2400 > 1024). Running this sequence through the model will result in indexing errors INFO:llama_index.token_counter.token_counter:> [get_response] Total LLM token usage: 2530 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total embedding token usage: 0 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total LLM token usage: 2530 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total embedding token usage: 0 tokens Observation: 横浜三塔は、キングの塔(神奈川県庁本庁舎)、クイーンの塔(横浜税関)、ジャックの塔(横浜市開港記念会館)の3つの塔で、横浜港のシンボルとして親しまれている。 Thought:So the 横浜三塔 are actually three towers: King's Tower (Kanagawa Prefectural Government Office), Queen's Tower (Yokohama Customs), and Jack's Tower (Yokohama Port Opening Memorial Hall). I should search for their history. Action: WikipediaSearch Action Input: "横浜三塔 歴史"INFO:llama_index.token_counter.token_counter:> [retrieve] Total LLM token usage: 0 tokens INFO:llama_index.token_counter.token_counter:> [retrieve] Total embedding token usage: 14 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total LLM token usage: 2604 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total embedding token usage: 0 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total LLM token usage: 2604 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total embedding token usage: 0 tokens Observation: 横浜三塔は、キングの塔(神奈川県庁本庁舎)、クイーンの塔(横浜税関)、ジャックの塔(横浜市開港記念会館)の3つの塔で、横浜港のシンボルとして親しまれています。ジャックの塔は、横浜町会所として建てられ、後に横浜市開港記念会館として再建されました。 Thought:So Jack's Tower was originally built as the Yokohama Town Hall and later rebuilt as the Yokohama Port Opening Memorial Hall. I should search for more information on the other two towers. Action: WikipediaSearch Action Input: "キングの塔 歴史" and "クイーンの塔 歴史"INFO:llama_index.token_counter.token_counter:> [retrieve] Total LLM token usage: 0 tokens INFO:llama_index.token_counter.token_counter:> [retrieve] Total embedding token usage: 25 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total LLM token usage: 2267 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total embedding token usage: 0 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total LLM token usage: 2267 tokens INFO:llama_index.token_counter.token_counter:> [get_response] Total embedding token usage: 0 tokens Observation: キングの塔とクイーンの塔は、それぞれ神奈川県庁本庁舎と横浜税関として建てられた建物であり、横浜三塔の一部として知られています。キングの塔は現在は神奈川県庁舎として使用されており、クイーンの塔は現在も横浜税関として使用されています。両塔とも、1934年に完成しました。 Thought:So King's Tower and Queen's Tower were originally built as the Kanagawa Prefectural Government Office and Yokohama Customs, respectively, and both were completed in 1934. I now know the final answer. Final Answer: 横浜三塔は、キングの塔(神奈川県庁本庁舎)、クイーンの塔(横浜税関)、ジャックの塔(横浜市開港記念会館)の3つの塔で、キングの塔とクイーンの塔は1934年に完成し、それぞれ神奈川県庁本庁舎と横浜税関として建てられました。ジャックの塔は、元々は横浜町会所として建てられ、後に横浜市開港記念会館として再建されました。
これをみると、
- まず横浜三塔の名前を調べる。
- 次にその歴史を調べて回答する。
というプロセスが正しく踏めていることが分かります。
まとめ
LlamaIndexとLangChainのAgentを組み合わせることで、文書を参照した多段推論を行う実験を簡易的にやってみました。
結果、LlamaIndexのquery単体ではうまくいかなかった多段推論をAgentと組み合わせることで実現することができました。
ただし、出力に間違った情報が含まれてしまっており完全な回答は得られていないため、今後改良すべきと考えられます。
MiniGPT-4を試してみた
GPT-4はマルチモーダルな情報処理が可能であるとされ、以下のように高度な画像認識ができるとOpenAIは主張しています(GPT-4 Technical Reportから引用)。

しかし2023年4月25日現在、GPT-4の画像認識機能はリリースされていません。 そんな中、MiniGPT-4という論文が登場しました(著者グループはOpenAIとは別のようです)。
これは学習済みの画像エンコーダ(ViTとQ-Formerから構成)と大規模言語モデル(Vicuna)を線形変換によって接続し、その接続層を学習させることでマルチモーダルな認識を実現した研究となっています。
また、デモが公開されており、ブラウザ上でこの機能を試せるようになっています。著者が公開しているサンプルを見ると、単に画像のキャプションを生成するだけでなく(これはBLIP-2など既存手法でも可能です)、ミーム画像の面白さを解説してもらったり、手書きのラフデザインからHTMLを作成してもらったりと多様なタスクが実現できそうです(以下に動画を引用)。
そこで、実際にデモを試してみてどれぐらいの性能があるのかを分析してみました。
基本的な画像の認識
まずは簡単なところから。犬の写真をuploadして画像の説明をお願いしたところ、犬種(ダックスフンド)・ビーチにいること・天気を含めて正確に回答してくれました。

日本語対応
なお、日本語で質問すると日本語で回答してくれますが、回答の正確さ・文章の自然さはだいぶ損なわれてしまうようです。
 英語で質問して日本語で答えてもらう形式でも同様でした。
英語で質問して日本語で答えてもらう形式でも同様でした。

複雑な画像の認識
映っている犬の数を回答してもらうと、「6匹」と実際とは違う数字が返ってきてしまいました。LLMが文字数のカウントが苦手なのと同様に、数を数えるのは苦手なのかもしれないです。

次はかなり難しいタスクとして、ポーカーの場面を説明してもらうことを試みてみました。
 「ポーカーをプレイしている」ことは分かっているようですが、ゲーム状況の把握までは厳しいようです。「スーツやTシャツを着ている」など関係ない言及もありました(hallucinationに近そうです)。
「ポーカーをプレイしている」ことは分かっているようですが、ゲーム状況の把握までは厳しいようです。「スーツやTシャツを着ている」など関係ない言及もありました(hallucinationに近そうです)。
LATEXの生成
次はあったらいいな、という機能として「手書きの数式からのLATEXの生成」を試してみました。Kullback-Leibler divergenceの式を読み込ませて、LATEXを書いてもらいました。

背景が黒なので少し分かりづらいですが、LATEX自体は生成してくれています。しかし入力画像の式とは全然違う式になってしまっています。頑張っていることは伝わるものの、まだまだみたいです。
GPT-4との比較
冒頭にも書いたGPT-4がやっている、ジョーク画像の回答をお願いしてみました。

MiniGPT-4の出力:
画像には、携帯電話を手に持ち、携帯電話の充電ポートに充電ケーブルを差し込んだ人物が写っています。充電ケーブルは電源に接続されており、電源はコンセントに差し込まれている。その人物は青いシャツを着ており、背中に黒いバックパックを背負っています。画像はローアングルで撮影されており、人物の顔とバックパックの上部が写っています。画像は明るく、人物とその携帯電話に明確な焦点が合っている。
この画像は、外出先で充電ケーブルを使って携帯電話を充電している人を示していて、面白いです。また、この人は片手で携帯電話を持ち、もう片方の手で充電ケーブルを持っているので、歩きながら充電ケーブルで携帯電話を充電しようとしているように見えるのも面白いところです。また、この画像では、人物が青いシャツと黒いバックパックを着用しているため、コミカルな面も加わっています。
全体的にがんばろうとしていることは伝わるものの、hallucinationが多く含まれ、また面白いポイントも外してしまっています。言語モデルがVicunaではGPT-4の性能にはなかなか追いつくのが難しいかもしれないです。あるいは、マルチモーダル認識のための学習方法にも改善の余地があるかもしれないです。
著者サンプルとの比較
最後に、著者サンプルで提示されていた、「問題点とその解決策を回答してもらう」タスクを試してみました。
 著者サンプルでは、感染症にかかってしまった植物の対処法を説明してくれています。
著者サンプルでは、感染症にかかってしまった植物の対処法を説明してくれています。

まず、同じ画像で試してみると同様にreasonableな出力が返ってきました。細かい違いはありますが、これは言語モデルが確率的に出力を生成するためですね。
 一方、似たようなタスクが使えそうな画像として、「割れたiphoneの画像」を入力すると「画面が割れている」ことは認識できるものの途中から同じ文章が繰り返されてしまい、出力として変になってしまいました。
一方、似たようなタスクが使えそうな画像として、「割れたiphoneの画像」を入力すると「画面が割れている」ことは認識できるものの途中から同じ文章が繰り返されてしまい、出力として変になってしまいました。
まとめ
この記事ではMiniGPT-4のデモを利用して、さまざまなタスクを試してみました。結果、基本的な画像認識はできているもののGPT-4のような多様なタスクへの適用はまだまだ発展途上、という印象を受けました。今後のモデル・手法のアップデートに期待したいところです。